


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Idomura, Yasuhiro; Ina, Takuya*; Ali, Y.*; Imamura, Toshiyuki*
Proceedings of International Conference for High Performance Computing, Networking, Storage, and Analysis (SC 2020) (Internet), p.1318 - 1330, 2020/11
Times Cited Count:1 Percentile:36.4(Computer Science, Information Systems)The multi-scale full-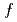 simulation of the next generation experimental fusion reactor ITER based on a five dimensional (5D) gyrokinetic model is one of the most computationally demanding problems in fusion science. In this work, a Gyrokinetic Toroidal 5D Eulerian code (GT5D) is accelerated by a new mixed-precision communication-avoiding (CA) Krylov method. The bottleneck of global collective communication on accelerated computing platforms is resolved using a CA Krylov method. In addition, a new FP16 preconditioner, which is designed using the new support for FP16 SIMD operations on A64FX, reduces both the number of iterations (halo data communication) and the computational cost. The performance of the proposed method for ITER size simulations with 0.1 trillion grids on 1,440 CPUs/GPUs on Fugaku and Summit shows 2.8x and 1.9x speedups respectively from the conventional non-CA Krylov method, and excellent strong scaling is obtained up to 5,760 CPUs/GPUs.
simulation of the next generation experimental fusion reactor ITER based on a five dimensional (5D) gyrokinetic model is one of the most computationally demanding problems in fusion science. In this work, a Gyrokinetic Toroidal 5D Eulerian code (GT5D) is accelerated by a new mixed-precision communication-avoiding (CA) Krylov method. The bottleneck of global collective communication on accelerated computing platforms is resolved using a CA Krylov method. In addition, a new FP16 preconditioner, which is designed using the new support for FP16 SIMD operations on A64FX, reduces both the number of iterations (halo data communication) and the computational cost. The performance of the proposed method for ITER size simulations with 0.1 trillion grids on 1,440 CPUs/GPUs on Fugaku and Summit shows 2.8x and 1.9x speedups respectively from the conventional non-CA Krylov method, and excellent strong scaling is obtained up to 5,760 CPUs/GPUs.
Matsumoto, Kazuya*; Idomura, Yasuhiro; Ina, Takuya*; Mayumi, Akie; Yamada, Susumu
Journal of Supercomputing, 75(12), p.8115 - 8146, 2019/12
Times Cited Count:2 Percentile:24.35(Computer Science, Hardware & Architecture)A communication-avoiding generalized minimum residual method (CA-GMRES) is implemented on a hybrid CPU-GPU cluster, targeted for the performance acceleration of iterative linear system solver in the gyrokinetic toroidal five-dimensional Eulerian code GT5D. In addition to the CA-GMRES, we implement and evaluate a modified variant of CA-GMRES (M-CA-GMRES) proposed in our previous study to reduce the amount of floating-point calculations. This study demonstrates that beneficial features of the CA-GMRES are in its minimum number of collective communications and its highly efficient calculations based on dense matrix-matrix operations. The performance evaluation is conducted on the Reedbush-L GPU cluster, which contains four NVIDIA Tesla P100 GPUs per compute node. The evaluation results show that the M-CA-GMRES is 1.09x, 1.22x and 1.50x faster than the CA-GMRES, the generalized conjugate residual method (GCR), and the GMRES, respectively, when 64 GPUs are used.
Ali, Y.*; Onodera, Naoyuki; Idomura, Yasuhiro; Ina, Takuya*; Imamura, Toshiyuki*
Proceedings of 10th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Systems (ScalA 2019), p.1 - 8, 2019/11
Times Cited Count:11 Percentile:96.82(Computer Science, Theory & Methods)Iterative methods for solving large linear systems are common parts of computational fluid dynamics (CFD) codes. The Preconditioned Conjugate Gradient (P-CG) method is one of the most widely used iterative methods. However, in the P-CG method, global collective communication is a crucial bottleneck especially on accelerated computing platforms. To resolve this issue, communication avoiding (CA) variants of the P-CG method are becoming increasingly important. In this paper, the P-CG and Preconditioned Chebyshev Basis CA CG (P-CBCG) solvers in the multiphase CFD code JUPITER are ported to the latest V100 GPUs. All GPU kernels are highly optimized to achieve about 90% of the roofline performance, the block Jacobi preconditioner is re-designed to extract high computing power of GPUs, and the remaining bottleneck of halo data communication is avoided by overlapping communication and computation. The overall performance of the P-CG and P-CBCG solvers is determined by the competition between the CA properties of the global collective communication and the halo data communication, indicating an importance of the inter-node interconnect bandwidth per GPU. The developed GPU solvers are accelerated up to 2x compared with the former CPU solvers on KNLs, and excellent strong scaling is achieved up to 7,680 GPUs on the Summit.
Ali, Y.*; Ina, Takuya*; Onodera, Naoyuki; Idomura, Yasuhiro
no journal, ,
Krylov subspace solvers for the pressure Poisson equation occupy 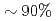 of the total computing cost in extreme scale multi-phase CFD simulation. To accelerate the Poisson solver, we port a Chebyshev Basis communication-avoiding Conjugate Gradient (CBCG) solver with block Jacobi (BJ) preconditioning on P100 GPUs. The CBCG solver consists of BJ preconditioning, Sparse Matrix Vector product (SpMV), and Tall-Skinny matrix operations. We re-design the BJ-preconditioner for thread-block parallelization and efficient coalescing data load, and apply batched gemm to the Tall-Skinny matrix operations. By these optimization, all main kernels achieved of the theoretical performance based on roofline estimation, and an order of magnitude speedup of the single node performance was obtained against CPU nodes.
of the total computing cost in extreme scale multi-phase CFD simulation. To accelerate the Poisson solver, we port a Chebyshev Basis communication-avoiding Conjugate Gradient (CBCG) solver with block Jacobi (BJ) preconditioning on P100 GPUs. The CBCG solver consists of BJ preconditioning, Sparse Matrix Vector product (SpMV), and Tall-Skinny matrix operations. We re-design the BJ-preconditioner for thread-block parallelization and efficient coalescing data load, and apply batched gemm to the Tall-Skinny matrix operations. By these optimization, all main kernels achieved of the theoretical performance based on roofline estimation, and an order of magnitude speedup of the single node performance was obtained against CPU nodes.
Ali, Y.*; Onodera, Naoyuki; Idomura, Yasuhiro; Ina, Takuya*; Imamura, Toshiyuki*
no journal, ,
Krylov solvers can account for up to 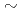 90% of the total computing cost in extreme scale nuclear CFD simulations. In order to accelerate such CFD codes, we ported the conventional Preconditioned Conjugate Gradient (PCG) and the two latest communication avoiding algorithms, the Preconditioned Chebyshev Basis communication-avoiding Conjugate Gradient (P-CBCG) and the Communication-Avoiding Generalized Minimal RESidual (CA-GMRES) methods, on to GPUs. In this talk, we discuss a trade-off between the performance portability and the performance improvement for implementations using OpenACC and CUDA, and show performance tests on the latest GPU supercomputers.
90% of the total computing cost in extreme scale nuclear CFD simulations. In order to accelerate such CFD codes, we ported the conventional Preconditioned Conjugate Gradient (PCG) and the two latest communication avoiding algorithms, the Preconditioned Chebyshev Basis communication-avoiding Conjugate Gradient (P-CBCG) and the Communication-Avoiding Generalized Minimal RESidual (CA-GMRES) methods, on to GPUs. In this talk, we discuss a trade-off between the performance portability and the performance improvement for implementations using OpenACC and CUDA, and show performance tests on the latest GPU supercomputers.
Idomura, Yasuhiro
no journal, ,
Communication-avoiding (CA) algorithms are key technologies towards extreme scale CFD simulations on future exascale machines, which are characterized by accelerated computation and relatively low communication bandwidth. In order to resolve this communication bottleneck, we developed two types of CA-based sparse matrix solvers on extreme scale nuclear simulations such as the five dimensional (5D) fusion plasma turbulence code GT5D and the 3D multi-phase thermal-hydraulic code JUPITER. One is a CA Krylov method, in which multiple basis vectors are generated and orthogonalized at once. By using this approach, one can avoid the bottleneck of All_Reduce communication, which is required at each iteration in the conventional Krylov method. The other is a CA multigrid (MG) method, in which the number of iteration or All_Reduce is reduced by improving the convergence property. In addition, MG implementation with a mixed precision approach reduces both computation and communication. By applying these CA solvers, the performances of GT5D and JUPITER were dramatically improved, and the strong scaling was extended up to the full system size of the Oakforest-PACS, which consists of 8,208 KNLs.
Idomura, Yasuhiro; Ali, Y.*; Ina, Takuya*; Imamura, Toshiyuki*
no journal, ,
Implicit finite difference solvers based on Krylov subspace methods occupy dominant computing costs in the Gyrokinetic Toroidal 5D full-f Eulerian code GT5D. Under the post-K project, advanced communication avoiding (CA) Krylov subspace methods have been developed for exascale computing platforms, which have limited inter-node communication performance compared with accelerated computation. In this work, we develop a new mixed precision CA-GMRES solver using a FP16 preconditioner, which dramatically reduces the number of iterations, and thus, halo data communications. We port the new solver on FUGAKU and Summit, and compare its performance against conventional solvers on existing muti/many-core processors.
